Comparing MT Based Translation Errors with Human Translation Errors
This is an important subject and one that needs ongoing examination and continuing study to get to real insight and find greater process efficiency. I hope that this post by Silvio Picinini will trigger further discussion and I also invite others who have information, and opinions to share on this subject, to step forward. In my observation of MT output over time, I have seen that MT produces a greater number of actual errors, but the types of errors most often generated by MT are easy to spot and clean up. Unlike the incorrect or inconsistent terminology and sometimes misunderstood source errors, that may often be hidden in the clear grammar and flow of a human translation. These human errors are much harder to find, and not as easy to correct without multiple stages of review by independent reviewers.
Please find the original article published on Multilingual magazine, July-August 2016, “Errors in MT and human translation”, pg. 46-50.
Post-editing could be defined as the correction of a translation suggested by a machine. When a translator receives a suggested translation from Google, Bing or another machine translation (MT) engine, the translator is working as a post-editor of that suggestion.
If instead the translator receives a suggestion from a translation memory (TM), the suggestion for that segment was created by a human translator in the past. If there is no suggestion from a TM, human translation is the creation of a translation by a human. If we now assume that a human translator and an MT engine “think” differently about the translation of a sentence, we can explore how a human translator makes different errors compared to a statistical machine translation process. If we make translators and post-editors more aware of the types of errors that they will find, they will be able to improve their translation quality.
Inconsistency
A human translator will likely go through a text and consistently translate the word “employee” with the same words in the target language, keeping his or her favorite word in mind and using it all the time in the translation. The MT engine, on the other hand, has no commitment to consistency. Statistical machine translation (SMT) is a popularity contest. So, in one sentence, the translation for “employee” may be the usual one. But the corpus used to train the engine may have come from governments, or from the European Parliament, for example. And governments may like to call employees “public servants.” If that is popular enough, the MT may choose this translation for some sentences. The translation will be inconsistent and could look something like “Company employees may only park on the east parking lot. If that is full, the public servant may park on the west parking lot.”
Thus, MT is more likely than humans to translate inconsistently.
However, here are two more thoughts on this. First, humans create inconsistencies also. If the TM contains translations made by several translators with different preferences for words, or contains translations created over a long period of time, chances are that there are inconsistencies in the TMs. Those inconsistencies will be accepted by the human translator.
Second, we are not weighing glossaries to one side or the other. The human translators could follow the glossary, or run glossary consistency checks and their translations would be consistent. But the same applies to post-editing.
Mistranslations
Many words have more than one meaning, and are defined as polysemous. The word “holder,” for example, may mean a person who owns a credit card (as in credit card holder), but it may also be a stand designed to hold an object, such as a plate holder. If you are thinking of items on eBay, you are most likely expecting the translation that means plate holder. A human translator will easily know the correct translation. The machine, however, may have a lot of training data related to finance or laws, and the most popular translation there could be the person. The MT could choose this most popular meaning and the result could be “fashion sponge holder with suction cup” translated as “fashion sponge card holder with suction cup.”
Thus, MT is more likely than humans to make mistranslation substitutions.
Words that are not to be translated
For a human translator, it is easy to know that Guess, Coach and Old Navy are brands, and therefore should not be translated into most target languages. As you know, SMT is a popularity contest, and the very common word “guess” likely appears quite frequently in the corpus that trained the SMT engine. The consequence — you guessed it — is that the MT is likely to translate the word instead of leaving it untouched because it is a brand.
This may happen with product names as well. Air Jordan sneakers could have the word Air translated. It could happen with the brand Apple versus the fruit apple, but since it is a popularity contest, the fruit may now be left untranslated instead of the iPhone having a fruit to go with it.
Thus, MT is more likely than humans to translate words that are not supposed to be translated.
Untranslated Words
The MT leaves out of vocabulary (oov) words untranslated, and humans will translate them. This will favor humans depending on how many oov words are present in the content to be translated. If the content is specific and different from the corpus used to train the engine, it is more likely that some words will not be known by the MT engine. But if the MT engine is well trained with the same kind of subject that is being translated, then the MT engine will minimize the number of untranslated words. On the other hand, MT takes the collective opinion into account. It may not translate words that are now commonly used untranslated, while a translator could be more traditional or old-fashioned and would translate the word. Would you translate “player” in “CD player” in your language? The word “player” used to be translated a few decades ago, but the usage changed and the English “CD player” is common now in many languages. The MT will learn from the corpus the most current and frequent usage, and may do better than a human translator. Overall, this issue still slightly favors the human side.
Thus, MT will leave more wrongly untranslated words than humans.
Gender and Number Agreement
The MT engine may learn from the corpus the correct translation for “beautiful skirt,” and skirt is a feminine word in many languages. However, the first time the source contains the combination “beautiful barometer,” it will pick from what it knows and it may translate beautiful as a feminine word. If barometer is masculine in the target language, this creates an error of gender agreement. The MT is more likely to make this error than a human translator, who intuitively knows the gender of objects. The same applies to singular and plural. English uses invariant adjectives for both, as in “beautiful skirt” and “beautiful skirts.” Thus, the MT engine may pick the singular translation for the adjective next to a plural noun. The MT is more likely to make a number agreement error than a human translator, who knows when singular or plural is needed.
Thus, MT will make more grammar errors than humans.
So far we have seen several examples of situations where humans translate better than MT engines. Now we will look at how a “self-correcting” property of MT, created from the popularity of a translation, can often do a better job than humans. A statistical MT engine can be seen as a “popularity contest” where the translation that is suggested is the most popular translation for a word or group of words present in the “knowledge” (corpus) that trained the MT engine.
Spelling
There are two types of spelling errors: the ones that create words that don’t exist (and can be caught by a spellchecker) and the errors that turn a word into another existing word. You may have turned “from” into “form” and “quite” into “quiet.” The first type, a pure spelling error made by MT would require that you have in the corpus more instances of the error than of the correction. Can you imagine a corpus that contains “porduct” 33 times and “product” only 32 times? So MT almost never makes a spelling error of this kind.
For the second type, humans turn words into other words, and the spellchecker will miss it. The MT engine will not make this error because it is not likely that the corpus will contain the misspelled word more frequently than the correct word for that context. This would require having “I am traveling form San Francisco to Los Angeles” more frequently in your corpus than you would have “I am traveling from San Francisco to Los Angeles” and which one is more likely to be popular in a corpus? The correct one. This is why MT will almost never make this kind of spelling error, while it is easy for a human translator to do so.
Thus, humans are more likely than MT to make spelling errors of any kind.
False Friends
False friends are words that look similar to a word in a different language, but mean something different. One example is the word “actual,” which means “real” in English. In Portuguese, the word atual means current or as of this moment. So a presentation mentioning “actual numbers” could be translated as “current numbers,” seriously changing the meaning and causing confusion. A human translator may make this error, but the MT would require the wrong translation for “actual” to be more popular in the corpus than the correct translation. You would need “actual numbers” to be translated more frequently as “current numbers” than as “real numbers.” Do you think this would happen? No, and that is why MT almost never falls for a false friend, while a human translator falls for it occasionally.
Thus, humans are more likely to make false friend errors than MT.
Fuzzy Match
There are several errors that result from the use of TM. These memories offer the human translator suggestions of translation that are similar to the segment they are translating. Similar does not mean equal, so if the suggested translation is a fuzzy match, the human translator must make changes. If they don’t make any change and accept the fuzzy match as it is, they risk making errors. There are three sub-types of errors to mention here:
Different terms. Think of a medical procedure where the next step is “Administer the saline solution to the patient.” If a fuzzy match shows “Administer the plasma to the patient,” this might risk a person’s life.
Opposite meaning. Think of “The temperature of the solution administered to the patient must stay below XX degrees.” If a fuzzy match shows “must stay above XX degrees,” this might risk a person’s life. For an eCommerce environment, this type of error could be a major issue: “This item will not be shipped to Brazil” versus “This item will be shipped to Brazil.”
Numbers that don’t match. Fuzzy matches from a year before may offer the translator a suggested translation of “iPhone 5” because that was the model from a year ago. The new model is the iPhone 6. If a fuzzy match is accepted with the wrong number, the translator is introducing an old model.
Thus, humans are much more likely to make errors for accepting fuzzy matches than MT.
Acronyms
MT may leave acronyms as they are, because they may not be present in the corpus. The MT engine has the advantage of having the corpus to clarify if an acronym should be translated as the same acronym as in the original, if it should be translated as a translated acronym or if it should be translated using the expanded words from the meaning of the acronym. Human translators may make errors here. If they do research, and the research does not clarify the meaning, the original acronym may be left in the translation. So this is an issue that favors the MT over humans, although not heavily.
The best solution for both humans and MT is to try to find the expanded form of the acronyms. This will help MT and humans produce a great and clear translation.
Thus, humans are slightly more likely to make errors translating acronyms than MT.
Terminology
MT may handle terminology remarkably better than a human translator. If an engine is trained with content that is specific to the subject being translated, and that has been validated by subject matter experts and by feedback from the target audience that reads that content, the specific terminology for that subject will be very accurate and in line with the usage. Add to this the fact that multiple translators may have created those translations that are in the corpus, and it becomes easy to see how an MT engine can do a better job with terminology than a single human translator, who often translates different subjects all the time and cannot be a subject matter expert on every subject.
Consider the following example:
English: “In photography and cinematography, a wide-angle lens refers to a lens whose focal length is substantially smaller than the focal length of a normal lens for a given film plane. This type of lens allows more of the scene to be included in the photograph.”
Portuguese machine translation: “Em fotografia e cinematografia, uma lente grande angular refere-se a uma lente cuja distância focal é substancialmente menor do que a distância focal de uma lente normal para um determinado plano do filme. Este tipo de lente permite que mais da cena a ser incluída na fotografia.”
In this example about photography, the MT already proposed the translation of wide-angle as grande angular, which is the term commonly used to refer to this type of lens. This translation means approximately “large angular.” A human translator knows the translations for the words wide and angle. The translator could then be tempted to translate the expression wide-angle literally as “wide angle” lenses (lente de ângulo amplo), missing the specific terminology used for the term. The same could happen for focal length. Portuguese usually uses distância focal, which means “focal distance." A human translator, knowing the translation for focal and length, would be tempted to translate this as comprimento focal and would potentially miss the specific terminology distância focal.
The quality of the terminology is, of course, based on the breadth and depth of the corpus for the specific subject. A generic engine such as Google or Bing may not do as well as an MT engine custom-trained for a subject. But overall, this is an issue that could favor the MT over humans.
Thus, humans are more likely to make errors for inappropriate terminology than MT.

Emerging technologies for post-editing
Now that we are aware of the issues, which are summarized in Figure 1, we are in a better position to look at emerging technologies related to post-editing. Post-editing work has one basic requirement: that the translator is able to receive MT suggestions to correct, if need be. This technology is now available integrated on several computer-aided translation (CAT) tools.
Considering the above, the next application of technology is the use of quality assurance (QA) tools to find MT errors. The technology itself is not new and has been available in CAT tools and in QA tools such as Xbench or Okapi CheckMate. What is new is the nature of checks that must be done with these tools. One example: in human translation you use a glossary to ensure the consistent translation of a term. In MT, you could create a check to find a certain polysemous word and the most likely wrong translation for it. Case frequently has the meaning of an iPhone case, but it is often wrongly translated with the meaning of a legal case. Your glossary entry for MT may say something like “find case in the source and legal case in the target.” This check is very different from a traditional check for human translation that looks for the use of the correct translation instead of the use of the “probably wrong” one.
After doing post-editing and finding errors, the last area of application of this technology is in the measurement of the post-editing, since what makes post-editing most attractive is the promise of increasing the efficiency of the translation process. We will briefly mention some of the main technologies being used or researched:
Post-editing speed tracking. The time spent post-editing can be tracked at a segment level. These numbers can then be compiled for a file. Some examples of use of this technology include the MateCat tool, the iOmegaT tool and the TAUS DQF platform.
MT confidence. Another technology worth mentioning is MT confidence scores. Based on several factors, an MT engine can express how confident it is on the translation of a certain word. If this confidence can be expressed in terms of coloring the words in a segment, this feature will help the post-editor focus on words with less confidence that are therefore more likely to require a change. This feature appeared in the CASMACAT project, as illustrated in Figure 2.

Edit distance. A concept that is not new but could be more used more often is the concept of edit distance. It is defined as the number of changes — additions, deletions or substitutions — made to a segment of text to create its final translated form. Comparing the final form of a post-edited segment to the original segment that came out of the MT engine provides a significant indication of the amount of effort that went into the post-editing task. The TAUS DQF platform uses edit distance scores.
We use the concept of edit distance in a broader sense here, indicating the amount of changes. This includes the “raw” number of changes made, but also includes normalized scores that divide the number of changes by the length of the text being changed, either in words or characters. The TER (Translation Edit Rate) score is used to measure the quality of MT output, and is an example of a normalized score.
The final quality that needs to be achieved through post-editing defines levels of “light post-editing” and “full post-editing.” There are discussions to define and measure these levels. The scores based on edit distance may provide a metric that helps in this definition. It is expected that the light post-editing should require fewer changes than a full post-editing, therefore the scores based on edit distance for a light post-editing should always be lower than the score for a full post-editing. Figure 3 below shows a hypothetical example with numbers.

Scores based on edit distance can be an important number in the overall scenario of measuring post-editing, combined with the measurements of speed. The TAUS DQF efficiency score proposed a combination of these measurements.
Silvio Picinini is a Machine Translation Language Specialist at eBay since 2013. With over 20 years in Localization, he worked on quality-focused positions for an LSP, and as an in-house English into Brazilian Portuguese translator for Oracle. A former quality engineer, Silvio holds degrees in electrical and electronic/software engineering.
LinkedIn: https://www.linkedin.com/in/silviopicinini
-----
It is common to see a focus on the errors that machine translation makes. But maybe there are also strengths in MT that can benefit translators and customers. So I wrote an article in Multilingual magazine comparing errors made by MT and human translators. The article is below, reproduced here with permission. Please find the original article published on Multilingual magazine, July-August 2016, “Errors in MT and human translation”, pg. 46-50.
Post-editing could be defined as the correction of a translation suggested by a machine. When a translator receives a suggested translation from Google, Bing or another machine translation (MT) engine, the translator is working as a post-editor of that suggestion.
If instead the translator receives a suggestion from a translation memory (TM), the suggestion for that segment was created by a human translator in the past. If there is no suggestion from a TM, human translation is the creation of a translation by a human. If we now assume that a human translator and an MT engine “think” differently about the translation of a sentence, we can explore how a human translator makes different errors compared to a statistical machine translation process. If we make translators and post-editors more aware of the types of errors that they will find, they will be able to improve their translation quality.
Inconsistency
A human translator will likely go through a text and consistently translate the word “employee” with the same words in the target language, keeping his or her favorite word in mind and using it all the time in the translation. The MT engine, on the other hand, has no commitment to consistency. Statistical machine translation (SMT) is a popularity contest. So, in one sentence, the translation for “employee” may be the usual one. But the corpus used to train the engine may have come from governments, or from the European Parliament, for example. And governments may like to call employees “public servants.” If that is popular enough, the MT may choose this translation for some sentences. The translation will be inconsistent and could look something like “Company employees may only park on the east parking lot. If that is full, the public servant may park on the west parking lot.”
Thus, MT is more likely than humans to translate inconsistently.
However, here are two more thoughts on this. First, humans create inconsistencies also. If the TM contains translations made by several translators with different preferences for words, or contains translations created over a long period of time, chances are that there are inconsistencies in the TMs. Those inconsistencies will be accepted by the human translator.
Second, we are not weighing glossaries to one side or the other. The human translators could follow the glossary, or run glossary consistency checks and their translations would be consistent. But the same applies to post-editing.
Mistranslations
Many words have more than one meaning, and are defined as polysemous. The word “holder,” for example, may mean a person who owns a credit card (as in credit card holder), but it may also be a stand designed to hold an object, such as a plate holder. If you are thinking of items on eBay, you are most likely expecting the translation that means plate holder. A human translator will easily know the correct translation. The machine, however, may have a lot of training data related to finance or laws, and the most popular translation there could be the person. The MT could choose this most popular meaning and the result could be “fashion sponge holder with suction cup” translated as “fashion sponge card holder with suction cup.”
Thus, MT is more likely than humans to make mistranslation substitutions.
Words that are not to be translated
For a human translator, it is easy to know that Guess, Coach and Old Navy are brands, and therefore should not be translated into most target languages. As you know, SMT is a popularity contest, and the very common word “guess” likely appears quite frequently in the corpus that trained the SMT engine. The consequence — you guessed it — is that the MT is likely to translate the word instead of leaving it untouched because it is a brand.
This may happen with product names as well. Air Jordan sneakers could have the word Air translated. It could happen with the brand Apple versus the fruit apple, but since it is a popularity contest, the fruit may now be left untranslated instead of the iPhone having a fruit to go with it.
Thus, MT is more likely than humans to translate words that are not supposed to be translated.
Untranslated Words
The MT leaves out of vocabulary (oov) words untranslated, and humans will translate them. This will favor humans depending on how many oov words are present in the content to be translated. If the content is specific and different from the corpus used to train the engine, it is more likely that some words will not be known by the MT engine. But if the MT engine is well trained with the same kind of subject that is being translated, then the MT engine will minimize the number of untranslated words. On the other hand, MT takes the collective opinion into account. It may not translate words that are now commonly used untranslated, while a translator could be more traditional or old-fashioned and would translate the word. Would you translate “player” in “CD player” in your language? The word “player” used to be translated a few decades ago, but the usage changed and the English “CD player” is common now in many languages. The MT will learn from the corpus the most current and frequent usage, and may do better than a human translator. Overall, this issue still slightly favors the human side.
Thus, MT will leave more wrongly untranslated words than humans.
Gender and Number Agreement
The MT engine may learn from the corpus the correct translation for “beautiful skirt,” and skirt is a feminine word in many languages. However, the first time the source contains the combination “beautiful barometer,” it will pick from what it knows and it may translate beautiful as a feminine word. If barometer is masculine in the target language, this creates an error of gender agreement. The MT is more likely to make this error than a human translator, who intuitively knows the gender of objects. The same applies to singular and plural. English uses invariant adjectives for both, as in “beautiful skirt” and “beautiful skirts.” Thus, the MT engine may pick the singular translation for the adjective next to a plural noun. The MT is more likely to make a number agreement error than a human translator, who knows when singular or plural is needed.
Thus, MT will make more grammar errors than humans.
So far we have seen several examples of situations where humans translate better than MT engines. Now we will look at how a “self-correcting” property of MT, created from the popularity of a translation, can often do a better job than humans. A statistical MT engine can be seen as a “popularity contest” where the translation that is suggested is the most popular translation for a word or group of words present in the “knowledge” (corpus) that trained the MT engine.
Spelling
There are two types of spelling errors: the ones that create words that don’t exist (and can be caught by a spellchecker) and the errors that turn a word into another existing word. You may have turned “from” into “form” and “quite” into “quiet.” The first type, a pure spelling error made by MT would require that you have in the corpus more instances of the error than of the correction. Can you imagine a corpus that contains “porduct” 33 times and “product” only 32 times? So MT almost never makes a spelling error of this kind.
For the second type, humans turn words into other words, and the spellchecker will miss it. The MT engine will not make this error because it is not likely that the corpus will contain the misspelled word more frequently than the correct word for that context. This would require having “I am traveling form San Francisco to Los Angeles” more frequently in your corpus than you would have “I am traveling from San Francisco to Los Angeles” and which one is more likely to be popular in a corpus? The correct one. This is why MT will almost never make this kind of spelling error, while it is easy for a human translator to do so.
Thus, humans are more likely than MT to make spelling errors of any kind.
False Friends
False friends are words that look similar to a word in a different language, but mean something different. One example is the word “actual,” which means “real” in English. In Portuguese, the word atual means current or as of this moment. So a presentation mentioning “actual numbers” could be translated as “current numbers,” seriously changing the meaning and causing confusion. A human translator may make this error, but the MT would require the wrong translation for “actual” to be more popular in the corpus than the correct translation. You would need “actual numbers” to be translated more frequently as “current numbers” than as “real numbers.” Do you think this would happen? No, and that is why MT almost never falls for a false friend, while a human translator falls for it occasionally.
Thus, humans are more likely to make false friend errors than MT.
Fuzzy Match
There are several errors that result from the use of TM. These memories offer the human translator suggestions of translation that are similar to the segment they are translating. Similar does not mean equal, so if the suggested translation is a fuzzy match, the human translator must make changes. If they don’t make any change and accept the fuzzy match as it is, they risk making errors. There are three sub-types of errors to mention here:
Different terms. Think of a medical procedure where the next step is “Administer the saline solution to the patient.” If a fuzzy match shows “Administer the plasma to the patient,” this might risk a person’s life.
Opposite meaning. Think of “The temperature of the solution administered to the patient must stay below XX degrees.” If a fuzzy match shows “must stay above XX degrees,” this might risk a person’s life. For an eCommerce environment, this type of error could be a major issue: “This item will not be shipped to Brazil” versus “This item will be shipped to Brazil.”
Numbers that don’t match. Fuzzy matches from a year before may offer the translator a suggested translation of “iPhone 5” because that was the model from a year ago. The new model is the iPhone 6. If a fuzzy match is accepted with the wrong number, the translator is introducing an old model.
Thus, humans are much more likely to make errors for accepting fuzzy matches than MT.
Acronyms
MT may leave acronyms as they are, because they may not be present in the corpus. The MT engine has the advantage of having the corpus to clarify if an acronym should be translated as the same acronym as in the original, if it should be translated as a translated acronym or if it should be translated using the expanded words from the meaning of the acronym. Human translators may make errors here. If they do research, and the research does not clarify the meaning, the original acronym may be left in the translation. So this is an issue that favors the MT over humans, although not heavily.
The best solution for both humans and MT is to try to find the expanded form of the acronyms. This will help MT and humans produce a great and clear translation.
Thus, humans are slightly more likely to make errors translating acronyms than MT.
Terminology
MT may handle terminology remarkably better than a human translator. If an engine is trained with content that is specific to the subject being translated, and that has been validated by subject matter experts and by feedback from the target audience that reads that content, the specific terminology for that subject will be very accurate and in line with the usage. Add to this the fact that multiple translators may have created those translations that are in the corpus, and it becomes easy to see how an MT engine can do a better job with terminology than a single human translator, who often translates different subjects all the time and cannot be a subject matter expert on every subject.
Consider the following example:
English: “In photography and cinematography, a wide-angle lens refers to a lens whose focal length is substantially smaller than the focal length of a normal lens for a given film plane. This type of lens allows more of the scene to be included in the photograph.”
Portuguese machine translation: “Em fotografia e cinematografia, uma lente grande angular refere-se a uma lente cuja distância focal é substancialmente menor do que a distância focal de uma lente normal para um determinado plano do filme. Este tipo de lente permite que mais da cena a ser incluída na fotografia.”
In this example about photography, the MT already proposed the translation of wide-angle as grande angular, which is the term commonly used to refer to this type of lens. This translation means approximately “large angular.” A human translator knows the translations for the words wide and angle. The translator could then be tempted to translate the expression wide-angle literally as “wide angle” lenses (lente de ângulo amplo), missing the specific terminology used for the term. The same could happen for focal length. Portuguese usually uses distância focal, which means “focal distance." A human translator, knowing the translation for focal and length, would be tempted to translate this as comprimento focal and would potentially miss the specific terminology distância focal.
The quality of the terminology is, of course, based on the breadth and depth of the corpus for the specific subject. A generic engine such as Google or Bing may not do as well as an MT engine custom-trained for a subject. But overall, this is an issue that could favor the MT over humans.
Thus, humans are more likely to make errors for inappropriate terminology than MT.
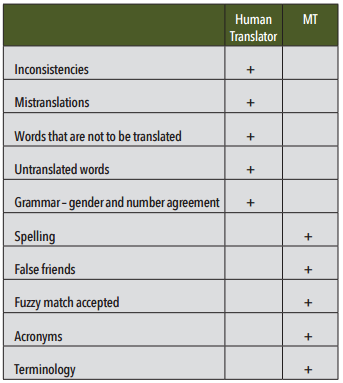
Figure 1: MT and human translation errors
Emerging technologies for post-editing
Now that we are aware of the issues, which are summarized in Figure 1, we are in a better position to look at emerging technologies related to post-editing. Post-editing work has one basic requirement: that the translator is able to receive MT suggestions to correct, if need be. This technology is now available integrated on several computer-aided translation (CAT) tools.
Considering the above, the next application of technology is the use of quality assurance (QA) tools to find MT errors. The technology itself is not new and has been available in CAT tools and in QA tools such as Xbench or Okapi CheckMate. What is new is the nature of checks that must be done with these tools. One example: in human translation you use a glossary to ensure the consistent translation of a term. In MT, you could create a check to find a certain polysemous word and the most likely wrong translation for it. Case frequently has the meaning of an iPhone case, but it is often wrongly translated with the meaning of a legal case. Your glossary entry for MT may say something like “find case in the source and legal case in the target.” This check is very different from a traditional check for human translation that looks for the use of the correct translation instead of the use of the “probably wrong” one.
After doing post-editing and finding errors, the last area of application of this technology is in the measurement of the post-editing, since what makes post-editing most attractive is the promise of increasing the efficiency of the translation process. We will briefly mention some of the main technologies being used or researched:
Post-editing speed tracking. The time spent post-editing can be tracked at a segment level. These numbers can then be compiled for a file. Some examples of use of this technology include the MateCat tool, the iOmegaT tool and the TAUS DQF platform.
MT confidence. Another technology worth mentioning is MT confidence scores. Based on several factors, an MT engine can express how confident it is on the translation of a certain word. If this confidence can be expressed in terms of coloring the words in a segment, this feature will help the post-editor focus on words with less confidence that are therefore more likely to require a change. This feature appeared in the CASMACAT project, as illustrated in Figure 2.

Figure 2: The CASMACAT project shows MT color-coded according to what is most likely to need post-editing
Edit distance. A concept that is not new but could be more used more often is the concept of edit distance. It is defined as the number of changes — additions, deletions or substitutions — made to a segment of text to create its final translated form. Comparing the final form of a post-edited segment to the original segment that came out of the MT engine provides a significant indication of the amount of effort that went into the post-editing task. The TAUS DQF platform uses edit distance scores.
We use the concept of edit distance in a broader sense here, indicating the amount of changes. This includes the “raw” number of changes made, but also includes normalized scores that divide the number of changes by the length of the text being changed, either in words or characters. The TER (Translation Edit Rate) score is used to measure the quality of MT output, and is an example of a normalized score.
The final quality that needs to be achieved through post-editing defines levels of “light post-editing” and “full post-editing.” There are discussions to define and measure these levels. The scores based on edit distance may provide a metric that helps in this definition. It is expected that the light post-editing should require fewer changes than a full post-editing, therefore the scores based on edit distance for a light post-editing should always be lower than the score for a full post-editing. Figure 3 below shows a hypothetical example with numbers.

Figure 3: Edit distance shows how much editing is required for a given machine-translated file.
Scores based on edit distance can be an important number in the overall scenario of measuring post-editing, combined with the measurements of speed. The TAUS DQF efficiency score proposed a combination of these measurements.
Silvio Picinini is a Machine Translation Language Specialist at eBay since 2013. With over 20 years in Localization, he worked on quality-focused positions for an LSP, and as an in-house English into Brazilian Portuguese translator for Oracle. A former quality engineer, Silvio holds degrees in electrical and electronic/software engineering.
LinkedIn: https://www.linkedin.com/in/silviopicinini


Comments
Post a Comment