Lilt Labs Response to my Critique of their MT Evaluation Study
I had a chat with Spence Green earlier this week to discuss the critique I wrote of their comparative MT evaluation, where I might have been a tad harsh, but anyway I think we were both able to see each other's viewpoints a little bit better, and I summarize the conversation below. This is followed by an MT Evaluation Addendum that Lilt has added to the published study to provide further detail on the specific procedures they followed in their comparative evaluation tests. These details should be helpful to those who want to replicate or modify and replicate, the test for themselves.
While I do largely stand by what I said, I think it is fair to allow Lilt to respond to the criticism to the degree that they wish to. I think some of my characterization may have been overly harsh (like the sheep-wolf image for example). My preference would have been that Lilt wrote this response directly rather than having me summarize the conversation, but I hope that I have captured the gist of our chat (which was mostly amicable) accurately and fairly.
The driving force behind the study were ongoing Lilt customer requests wanting to know how the various MT options compared. Spence ( Lilt) said that he attempted to model their evaluation along the lines of the NIST "unrestricted track" evaluations and he stated repeatedly that they tried to be as transparent and open as possible so that others could replicate the tests for themselves. I did point out that one big difference here is that unlike NIST, we have one company here comparing themselves to their competitors also happens to be managing the evaluation. Clearly a conflict of interest, but mild compared to what is going on in Washington DC now. Thus, however well-intentioned and transparent the effort may be, the chances of protest are always going to be high with such an initiative.
Spence did express his frustration with how little understanding there is of (big) data in the localization industry which does make these kinds of assessments and any discussion on core data issues problematic.
Some of the specific clarifications he provided are listed below:
While I do largely stand by what I said, I think it is fair to allow Lilt to respond to the criticism to the degree that they wish to. I think some of my characterization may have been overly harsh (like the sheep-wolf image for example). My preference would have been that Lilt wrote this response directly rather than having me summarize the conversation, but I hope that I have captured the gist of our chat (which was mostly amicable) accurately and fairly.
The driving force behind the study were ongoing Lilt customer requests wanting to know how the various MT options compared. Spence ( Lilt) said that he attempted to model their evaluation along the lines of the NIST "unrestricted track" evaluations and he stated repeatedly that they tried to be as transparent and open as possible so that others could replicate the tests for themselves. I did point out that one big difference here is that unlike NIST, we have one company here comparing themselves to their competitors also happens to be managing the evaluation. Clearly a conflict of interest, but mild compared to what is going on in Washington DC now. Thus, however well-intentioned and transparent the effort may be, the chances of protest are always going to be high with such an initiative.
Spence did express his frustration with how little understanding there is of (big) data in the localization industry which does make these kinds of assessments and any discussion on core data issues problematic.
Some of the specific clarifications he provided are listed below:
- SwissAdmin was chosen as it was the "least bad" data that we could have used to enable us to conduct a test with some level of adaptation that everybody could replicate. Private datasets were not viable because the owners did not want to share the data with the larger community to enable test replication. We did argue over whether this data was really representative of localization content, but given the volumes of data needed and need to have it easily available to all, there was not a better data resource available. To repeat, SwissAdmin was the least bad data available. Spence pointed out that:
- Observe that the LREC14 paper has zero citations according to Google Scholar
- Compare adaptation gains to three different genres in their EMNLP15 paper.
- It is clear that Google NMT is a "really good" system and sets a new bar for all the MT vendors to measure against, but Spence felt that it was not accurate to say that Google is news-focused as it has a much broader data foundation, from the extensive web crawling data acquisition that supports the engine. He also challenged my conclusion that since GNMT was so good it was not worth the effort with other systems. It is clear that an adaptation/ customization effort with only 18,000 segments is unlikely to outperform Google and we both agreed that most production MT systems in use will have much more data to support adaptation. (I will also mention that the odds of do-it-yourself Moses systems being able to compete on quality now are even less likely and that Moses practitioners should assess if DIY is worth the time and resources at all if they have not already realized this. Useful MT systems will almost by definition need an expert foundation and expert steering.)
- He also pointed out that there are well-documented machine learning algorithms that can assess if the MT systems have certain data in their training sets and that these were used to determine that the SwissAdmin data was suitable for the test.
- While they were aware of the potential for bias in the evaluation study they made every effort to be as open as possible about the evaluation protocol and process.Others can replicate the test if they choose to.
- Lilt provides an explanation of the difficulties associated with running the SDL Interactive system in a footnote in the Evaluation Addendum attached below.
- We also agreed that 18,000 segments (used for adaptation/ customization here) may not be quite enough to properly customize an MT engine and that in most successful MT engines a much larger volume of data is used to produce clear superiority over GNMT and other continuously evolving public MT engines. This again points to the difficulty of doing such a test with "public" data, the odds of finding the right data in sufficient volume, that everyone can use, are generally not very good.
- Microsoft NMT was not initially included in the test because it was not clear how access was gained and he pointed me to the developer documentation to show how the Google docs were much clearer and easier to determine how to access the NMT systems. This lack of documentation may have been addressed since the test was run.
- One of my independent observations on who really "invented" Adaptive MT also seemed troublesome to Spence. I chose to focus on Microsoft and SDL patents as proof that others were thinking about this and had very developed ideas on how to implement this long before Lilt came into existence. However, he pointed quite correctly and much more accurately that there were others who were discussing this approach from as early as the 1950's and that Martin Kay and Alan Melby, in particular, were discussing this in the 1970's. He pointed out a paper that details this and provides historical context on the foundational thinking behind Adaptive and Interactive MT. This to me does suggest that any patent in this area is largely built on the shoulders of these pioneers. Another paper by Martin Kay from 1980 provides the basic Adaptive MT concept on page 18. Also, he made me aware of Transtype: (the first statistical interactive/ adaptive system, a project that began in 1997 in Canada). For those interested you can get details on the project here:
- the canonical work,
- EMNLP-02 best paper nominee,
- EMNLP-04 paper on adaptation.
Finally, all other vendors are welcome to reproduce, submit, and post results. We even welcome an independent third-party taking over this evaluation.
Spence Green
It may be that some type of comparative evaluation will become more important for the business translation industry as users weigh different MT technology options, and possibly could provide some insight on relative strengths and weaknesses. However, the NIST evaluation model is very difficult to implement in the business translation (localization) use case, and I am not sure if it even makes sense here. There may be an opportunity for a more independent body that has some MT expertise to provide a view on comparative options, but we should understand that MT systems can also be tweaked and adjusted to meet specific production goals and that the entire MT system development process is dynamic and evolving in best practice situations. Source data can and should be modified and analyzed to get better results, systems should be boosted in weak areas after initial tests and continuously improved with active post-editor involvement to build long-term production advantage, rather than just doing this type of instant snapshot comparison. What might matter much more in a localization setting is how quickly and easily a basic MT system can be updated and enhanced to be useful in business translation use-case production scenarios. This kind of a quick snapshot view has a very low value in that kind of a user scenario where it is understood that any MT system needs more work than just throwing some TM at it BEFORE putting it into production.


-------------------------
Experimental Design
We evaluate all machine translation systems for English-French and English-German. We report case-insensitive BLEU-4 [2], which is computed by the mteval scoring script from the Stanford University open source toolkit Phrasal (https://github.com/stanfordnlp/phrasal). NIST tokenization was applied to both the system outputs and the reference translations.
We simulate the scenario where the translator translates the evaluation data sequentially from the beginning to the end. We assume that she makes full use of the resources the corresponding solutions have to offer by leveraging the translation memory as adaptation data and by incremental adaptation, where the translation system learns from every confirmed segment.
System outputs and scripts to automatically download and split the test data are available at: https://github.com/lilt/labs.
System Training
Production API keys and systems are used in all experiments. Since commercial systems are improved from time to time, we record the date on which the system outputs were generated.
Lilt
The Lilt baseline system available through the REST API with a production API key. The system can be reproduced with the following series of API calls:
- POST /mem/create (create new empty Memory)
- For each source segment in the test set:
- GET /tr (translate test segment)
Date: 2016-12-28
Lilt adapted
The Lilt adaptive system available through the REST API with a production API key. The system simulates a scenario in which an extant corpus of source/target data is added for training prior to translating the test set. The system can be reproduced with the following series of API calls:
- POST /mem/create (create new empty Memory)
- For each source/target pair in the TM data:
- POST /mem (update Memory with source/target pair)
- For each source segment in the test set:
- GET /tr (translate test segment)
Date: 2017-01-06
Lilt Interactive
The Lilt interactive, adaptive system available through the REST API with a production API key. The system simulates a scenario in which an extant corpus of source/target data is added for training prior to translating the test set. To simulate feedback from a human translator, each reference translation for each source sentence in the test set is added to the Memory after decoding. The system can be reproduced with the following series of API calls:
- POST /mem/create (create new empty Memory)
- For each source/target pair in the TM data:
- POST /mem (update Memory with source/target pair)
- For each source segment in the test set:
- GET /tr (translate test segment)
- POST /mem (update Memory with source/target pair)
Date: 2017-01-04
Google
Google’s statistical phrase-based machine translation system. The system can be reproduced by querying the Translate API:
- For each source segment in the test set:
- GET https://translation.googleapis.com/language/translate/v2?model=base
Date: 2016-12-28
Google neural
Google’s neural machine translation system (GNMT). The system can be reproduced by querying the Premium API:
- For each source segment in the test set:
- GET https://translation.googleapis.com/language/translate/v2?model=nmt
Date: 2016-12-28
Microsoft
Microsoft’s baseline statistical machine translation system. The system can be reproduced by querying the Text Translation API:
- For each source segment in the test set:
- GET /Translate
Date: 2016-12-28
Microsoft adapted
Microsoft’s statistical machine translation system. The system simulates a scenario in which an extant corpus of source/target data is added for training prior to translating the test set. We first create a new general category project on Microsoft Translator Hub, then a new system within that project and upload the translation memory as training data. We do not provide any tuning or test data so that they are selected automatically. We let the training process complete and then deploy the system (e.g., with category id CATEGORY_ID). We then decode the test set by querying the Text Translation API, passing the specifier of the deployed system as category id:
- For each source segment in the test set:
- GET /Translate?category=CATEGORY_ID
Date: 2016-12-30 (after the migration of Microsoft Translator to the Azure portal)
Microsoft neural
Microsoft’s neural machine translation system. The system can be reproduced by querying the Text Translation API with the “generalnn” category id:
- For each source segment in the test set:
- GET /Translate?category=generalnn
Date: 2017-02-20
Systran neural
Systran’s “Pure Neural” neural machine translation system. The system can be reproduced through the demo website. We manually copy-and-pasted the source into the website in batches of no more than 2000 characters. We verified that line breaks were respected and that batching had no impact on the translation result. This comprised considerable manual effort and was performed over the course of several days.
Date(s): en-de: 2016-12-29 - 2016-12-30; en-fr: 2016-12-30 - 2017-01-02
SDL
SDL’s Language Cloud machine translation system. The system can be reproduced through a pre-translation batch task in Trados Studio 2017.
Date: 2017-01-03
SDL adapted
SDL’s “AdaptiveMT” machine translation system, which is accessed through Trados Studio 2017. The system can be reproduced by first creating a new AdaptiveMT engine specific to a new project and pre-translate the test set. The new project is initialized with the TM data. We assume that the local TM data is propagated to the AdaptiveMT engine for online retraining. The pre-translation batch task is used to generate translations for all non-exact matches. Adaptation is performed on the TM content. In the adaptation-based experiments, we did not confirm each segment with a reference translation due to the amount of manual work that would have been needed in Trados Studio 2017. (1)
(1) We were unable to produce an SDL interactive system comparable to Lilt interactive. We first tried confirming reference translations in Trados Studio. However, we found that that model updates often requires a minute or more of processing. Suppose that pasting the reference into the UI requires 15 seconds, and the model update requires 60 seconds. For en-de, 1299 * 75 / 3600 = 27.1 hours would have been required to translate the test set. We then attempted to write interface macros to automate the translation and confirmation of segments in the UI, but the variability of the model updates, and other UI factors such as scrolling prevented successful automation of the process. The absence of a translation API prevented crowd completion of the task with Amazon Mechanical Turk.
The Lilt adapted, Microsoft adapted and SDL adapted systems are most comparable as they were adapted in batch mode, namely by uploading all TM data, allowing training to complete, and then decoding the test set. Of course, other essential yet non user-modifiable factors such as the baseline corpora, optimization procedures, and optimization criteria can and probably do differ.
Test Corpora
We defined four requirements for the test corpus:
- It is representative of typical paid translation work
- It is not used in the training data for any of the competing translation systems
- The reference translations were not produced by post-editing from one of the competing machine translation solutions
- It is large enough to permit model adaptation
Since all systems in the evaluation are commercial production systems, we could neither enforce a common data condition nor ensure the exclusion of test data from the baseline corpora as in requirement (2). Nevertheless, in practice it is relatively easy to detect the inclusion of test data in a system’s training corpus via the following procedure:
- Select a candidate test dataset
- Decode test set with all unadapted systems and score with BLEU
- Identify systems that deviate significantly from the mean (in our case, by two standard deviations)
- If a system exists in (3):
- Sample a subset of sentences and compare the MT output to the references.
- If reference translations are present,
- Eliminate the candidate test dataset and go to (1)
- Accept the candidate test dataset
Starting in November 2016, we applied this procedure to the eight public datasets described in Appendix B. The ninth corpus that we evaluated was SwissAdmin, which both satisfied our requirements and passed our data selection procedure.
SwissAdmin [http://www.latl.unige.ch/swissadmin/] is a multilingual collection of press releases from the Swiss government from 1997-2013. We used the most recent press releases. We split the data chronologically, reserving the last 1300 segments of the 2013 articles as English-German test data, and the last 1320 segments as English-French test set. Chronological splits are standard in MT research to account for changes in language use over time. The test sets were additionally filtered to remove a single segment that contained more than 200 tokens. The remainder of articles from 2011 to 2013 were reserved as in-domain data for system adaptation.
| SwissAdmin | en-de | en-fr | ||
TM | test | TM | test | |
#segments | 18,621 | 1,299 | 18,163 | 1,319 |
#words | 548,435 / 482,692 | 39,196 / 34,797 | 543,815 / 600,585 | 40,139 / 44,874 |
Results
(Updated with Microsoft neural MT)
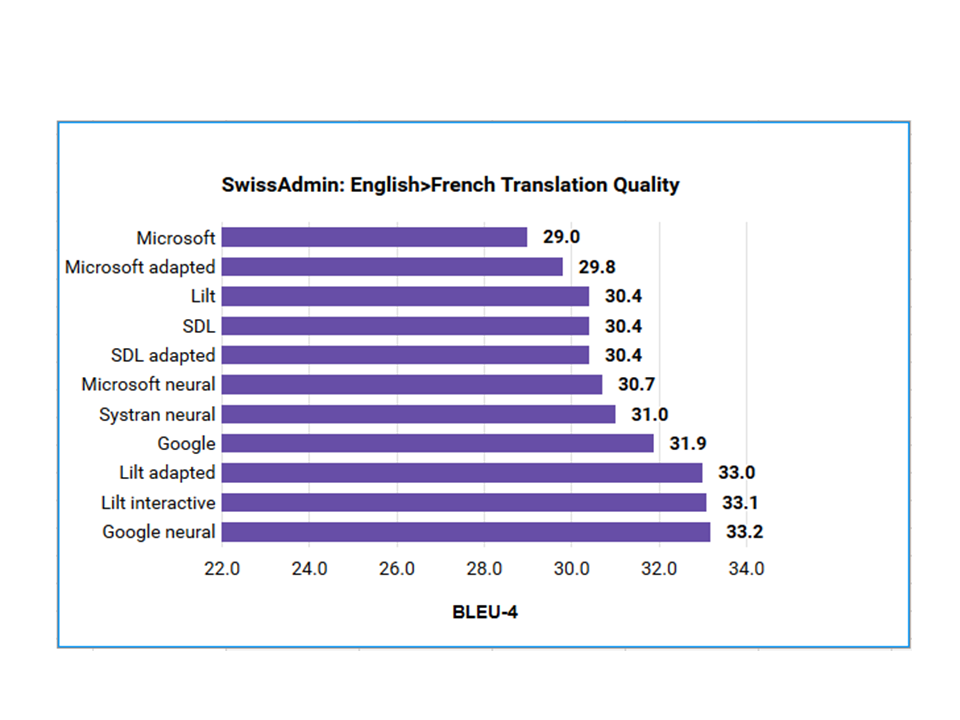
SwissAdmin | English->German | English->French |
Lilt | 23.2 | 30.4 |
Lilt adapted | 27.7 | 33.0 |
Lilt interactive | 28.2 | 33.1 |
Google | 23.7 | 31.9 |
Google neural | 28.6 | 33.2 |
Microsoft | 24.8 | 29.0 |
Microsoft adapted | 27.6 | 29.8 |
Microsoft neural | 23.8 | 30.7 |
Systran neural | 24.2 | 31.0 |
SDL | 22.6 | 30.4 |
SDL adapted | 23.8 | 30.4 |

Appendix B: Candidate Datasets
The following datasets were evaluated and rejected according to the procedure specified in the Test Corpora section:
- JRC-Acquis
- PANACEA English-French
- IULA Spanish-English Technical Corpus
- MuchMore Springer Bilingual Corpus
- WMT Biomedical task
- Autodesk Post-editing Corpus
- PatTR
- Travel domain data (from booking.com and elsewhere) crawled by Lilt


Comments
Post a Comment